
So far databases have been confusing. The purpose of a database is to store information that programs can access, modify and use. It appears as though computers (and by extention, databases) only enjoy storing information in the form of tables. Tables seem to be the way that computers understand and organize the information that it holds. Sadly this is yet another point of divergence between my self and the computer.
However, I have been actively trying to understand how they function and respond and will do my best to explain it so that even the least mathematically (or tabley) able individuals like myself can see the purpose and use for them.

Overview
Databases can store any data! So I want to organize my Christmas Gift Ideas for my friends and family. If I create a datatable I can keep track of what I want to get and where I can get it.
Because computers like tables we will put this in a table:
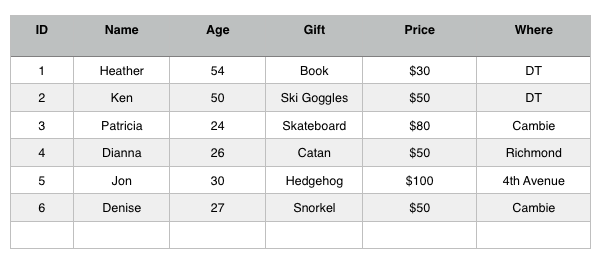
Now I can easily access the information that I need. Lets say I am heading to Cambie then I can get only the gift ideas that can be purchased there! I can also check how much money I will need to bring with me ($130).

Or just the gifts that are Downtown:

So that is the purpose of databases: to make it easier to access, modify and maniputlate your data.
Breaking Down A Table
Because we are going to have to work with tables alot, it's a good idea to learn the lingo that computers use for table properties.
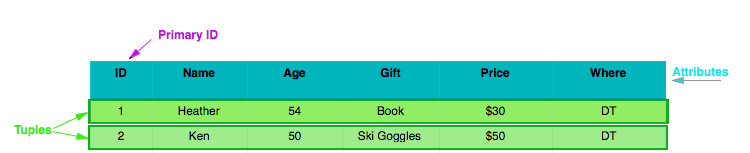
Attributes
The Attributes are the first row of the table and define the (attributes of the) data in each of the columns that will be inputed. For example in the table above all the data in column two will be a Name of someone I want to give a gift to.
Furthermore, each attribute has a type (the type of data that will be inputed). For a name, the type would be text, and for Age, the type would be integer (more on this later).
Tuples
The Tuples are the rows with data. In the above table there are two tuples. Since we might need to use the information in one table again, it is important to create a unique Primary ID for each tuple so the data can easily be accessed later.
Primary ID
It is important to create Primary ID's so that you can request specific information. Although any attribute with a unique set of values could act as a primary key, it is a good idea create a new ID field.
This is because an attribute that have a unique set of values right now, might now later. For example, in my current table, everyone has different names, so the names could act as a primary key, but if I met someone that I wanted to give a gift that was named Ken, then there would be two people named Ken on the table. Now if I asked what gift am I getting Ken, it wouldn't know which Ken I was talking about and the data would get confused.
The Primary ID's create your y index while the specific attribute creates your x index. So if I ask what "gift" am I getting the ID "2" we can see that its "ski goggles".
Relational Databases
Now that we know how a table works, we can start trying to relate different tables together.
Creating the Relational Schema
The Schema is the structure of your database and the types of relationships your data will have (from Introduction to Databases a lecture from Standford Mini-Series) It is how your tables will interact to give you your desired output. It is the tables and the attributes you want to have before having the data entered. The schema is typically set up at the beginning, and doesn't change much over time, while the data you put in is constantly being updated and modified (Introduction to Databases).
It is a good idea to draw out how the schema will look and act so you can visually see what is/ will happen.
So if we go back to the original table I have specific gifts for specific people:
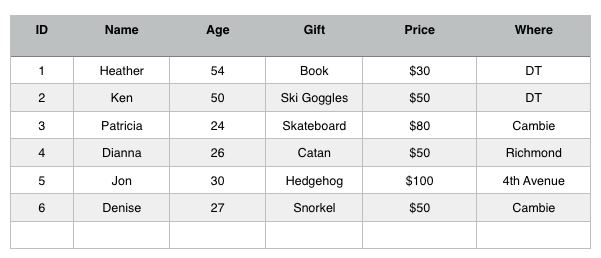
But now lets say instead of a Christmas gift list, I want to just create a gift list. As I see things I think people might like I write them down so I remember. I may give the gift as a New Years gift, as congratualtions or for their birthday. So now I want to split up my table a bit, so I can have multiple gifts that each person might want. The splitting up of cumbersome and complex tables into more smaller tables to reduce redundancy is known as Database Normalisation (this is a great 10 minute video explaining Database Normalisation by Mr. Woo)

Another thing that is good to show in the schema is the attributes of each table, that is the kind of information we want to know for each table.
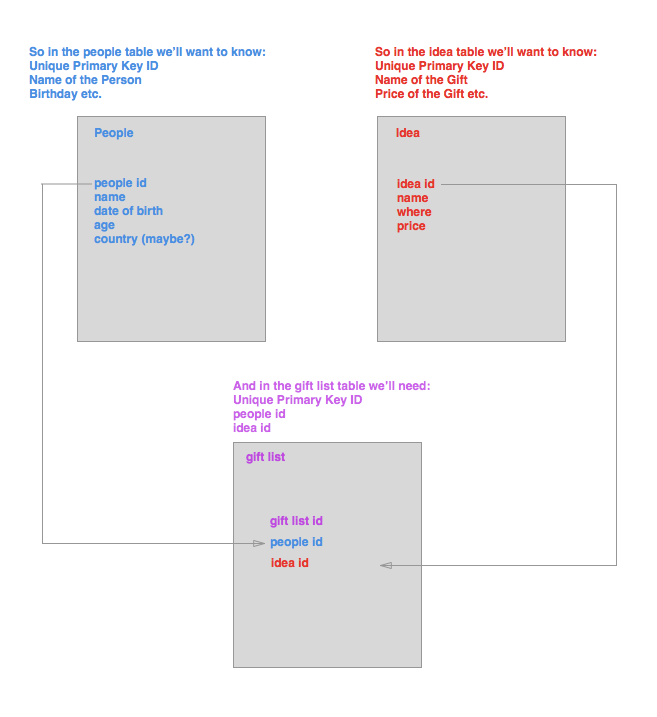
Inputing the Data
Now lets look at how this would look with the data. Remember that the list of attributes in each of these representations will become the first row of each table.
Following our Data Schema we will have two tables one for people and one for gift ideas.
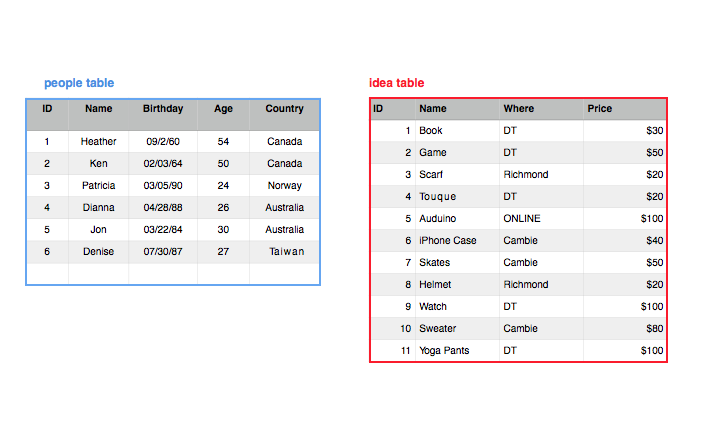
We then want to see the relation (ie. what does Heather actually want from my gift list). So we create that third table, gifts that shows the relationship of the data from the people table and the idea table.
* Note: When a primary key is used in another table it becomes a foreign key. For example, the p _id, and i _id in the above table are foreign keys in the gift _list table, but are primary keys in their respective tables.
So now we have gifts linked for two of my friends on my people list. We would go through and do that for every person on my people list and match them to one or more of the gifts on my idea list.
Types of Table Relations
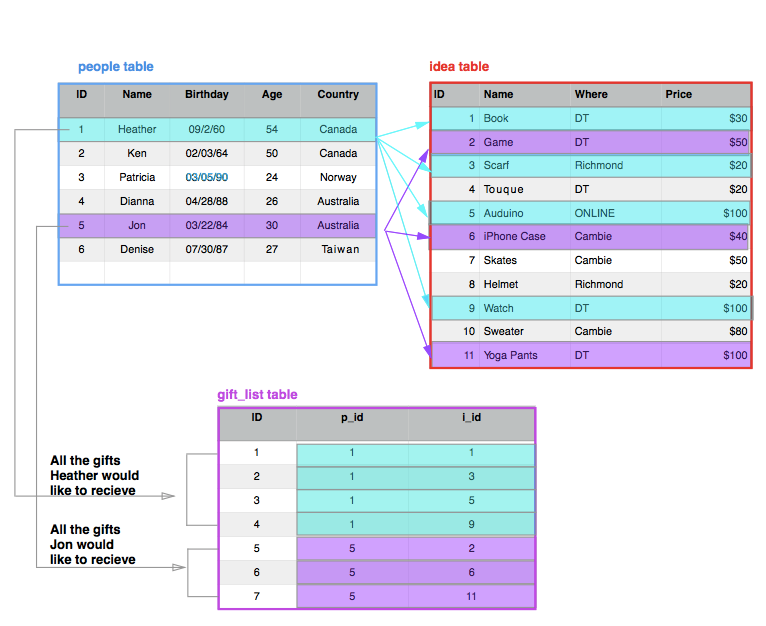
In the previous example, Jon is not interested in anything that Heather is. Therefore all of the i_id's are unique. However, as we start inputting more people there is an overlap of gifts:
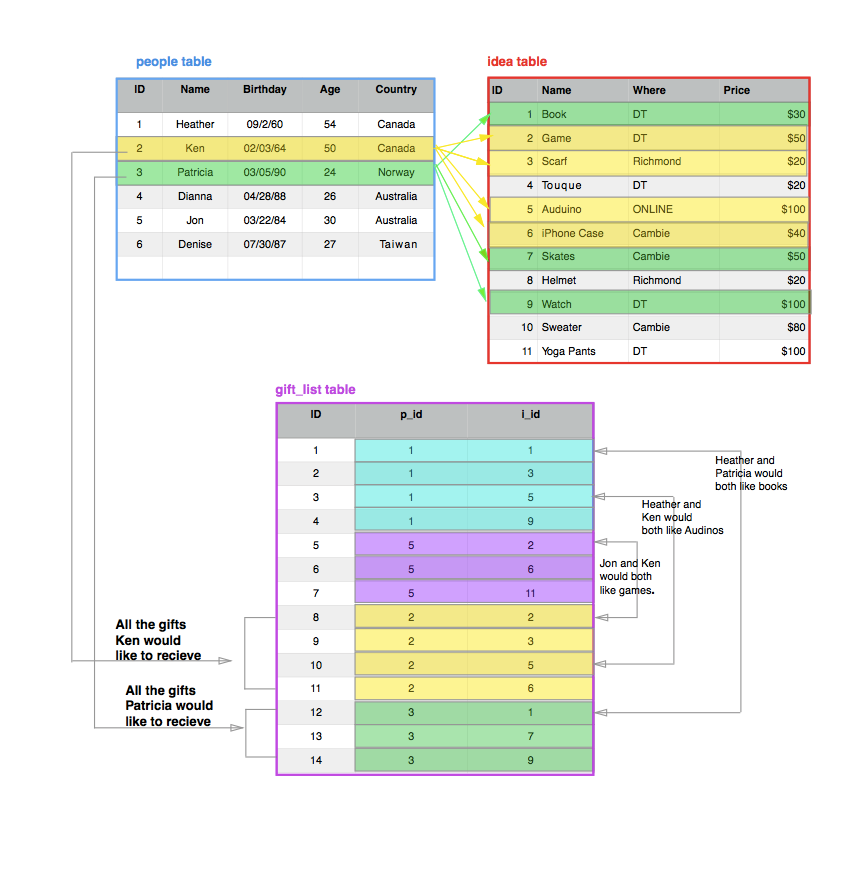
Therefore, we can see that the people and the idea tables have a many to many relationship. This means that many people could want many things and those things may overlap (ie. Ken and Jon both want games, Patricia and Heather both want books etc.). When there is a many to many relationship, we need to create an intermediate (gift_list) table which is able to show these relationships clearly.
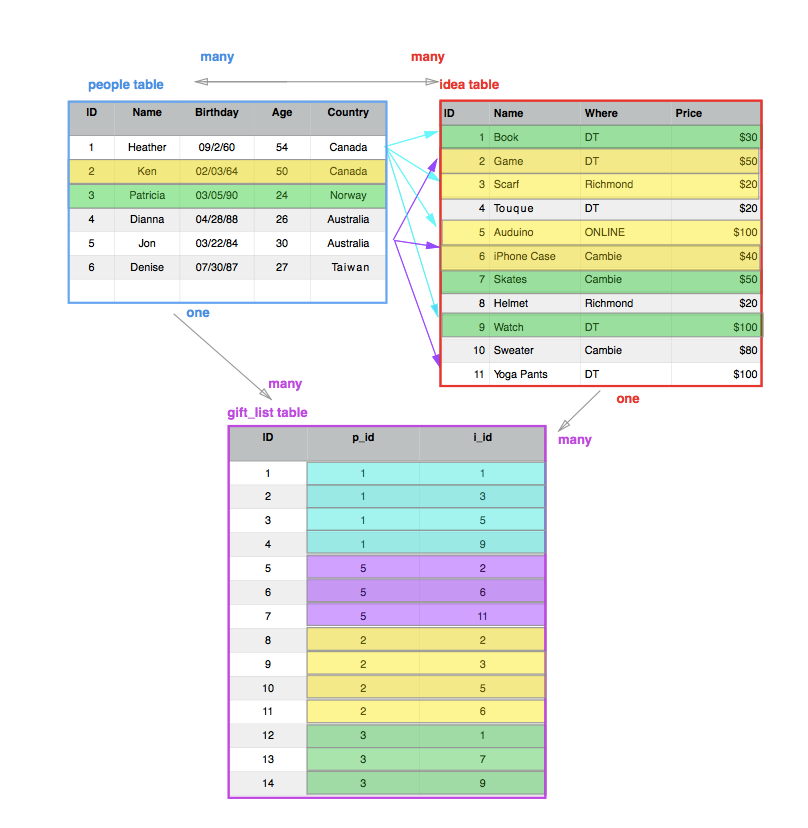
The relations can exist within the columns of a table AND between tables (Wikipedia)There are three types of relations:
one-to-one: In a one-to-one relationship, there is one set of data per one ID.
one-to-many: In a one-to-many relationship, there is one, ID but that could be represented many times. For example, in the people table, the Country is a one-to-many relationship, a person can only be living in one place, but many people can be living in the same place (ie. Ken and Heather both live in Canada, but Ken doesn't live in Canada and Australia).
many-to-many: In a many-to-many relationship, the data can be represented many times for both sets of ID. For example, Heather wants multiple gifts(a book, an Arduino, a scarf), as well as a single gift (a book), has multiple people it could go to (Patricia, Heather). For many-to-many relationships, we need to create an intermediate table to show the results. In this case each of these relationships become many-to-one relationships with the intermediate table (ie. the Heather ID can be seen many times in the gift_list table, but the p _id only has one meaning: Heather).